CS50-Week5
最后更新时间:
文章总字数:
预计阅读时间:
完成了指针的部分!真的很难,这一部分反复看了五六遍视频,又看 Notes,好在完全搞明白了。
Notes
链表与内存分配
目标:创建一个链表,像其中存入 10 个数且不发生内存泄漏
思路:创建一个列表 list ,再创建一个 node 节点用于初始化链表数值,接着进入 for 循环,在循环内设置赋值语句。
以设置一个 1,2,3,4,5……的链表举例,设置一个用于分配数值的节点 node *n,访问 n 内的数值,然后将 list 指向该节点,指向后 list 需要继续向下指,为能继续创建节点,将 n 的 next 地址设置为 list,然后将 n 的地址赋给 list
读取链表需要设置一个临时指针 ptr,将 ptr 初始化为 list,进入循环,当 ptr 不为空时:打印 ptr 所指的数字值,然后将所指 next 赋给 ptr,使其指向下一位置,循环
内存释放:每释放一个节点前需要记录下一节点的地址,设置 next 节点,在释放当前节点前记录当前节点 ptr 的 next 所指,然后释放当前内存,将 next 记录的地址赋给 ptr,循环
新建一个 node 结构体,包含 int number ;node *next;
即一个数字,一个 node 型地址,自引用需要使用语法:
1 | |
1 | |
树状二分
每个节点带有左右指针,递归的分配,若待查数值大于当前地址的数值,读取右地址,并返回……
当值相等时,返回。
对于一些特殊情况,例如所有值均在某一侧使树形成链表结构,可以优化,将中间值设置为根……
哈希
作为字典的一种,具有键值对 key-value,即索引与值
对于人名排序,设置 26 个 bucket,存储人名的首字母。理想情况下,可以将 O(n)将为 O(1)。
对于多个相同数字母的人名,将原先的 ABC 哈希表进行扩展,为 AA,AB,AC……
对于哈希表,哈希函数为每个首字母的名字分配对应 bucket 值 1,2,3…26.
实现:
途中发现的问题:
you
char list 和 char *list 有什么区别
ddb
在 C 语言中,char list 和 char *list 是两种不同的数据类型。
char list 表示一个字符变量,它可以存储一个字符。
而 char *list 是一个字符指针,它存储的是字符的地址,通常用于指向一个字符数组的开始。这样,通过这个指针,我们可以访问和操作这个字符数组。
这两者的主要区别在于它们存储的内容和它们的用途。
char 只能存储单字符,将其设置为地址变量就可以在首字母后面不断存储字符了
Trie-前缀树
更高级的字典树结构,每个节点都是一个数组,每个数组可以指向像一个数组,对于查找人们即对每一个字母排序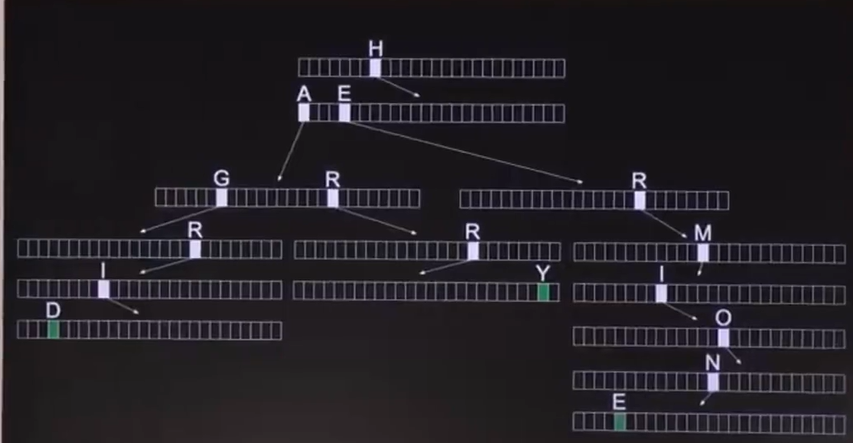
至此。
Psets
Inheritance
Before coding
目标:家族血型遗传推测
细节:
- 函数
create_family接受一个整数作为输入,并返回对 person 的下一代的指针 - 每个 person 都有符合遗传学的 alleles,第 0 代的 allele 由
random_allele函数随机选择 - 第 0 代的根设置为 NULL
Vocabulary
allele
indent
recursion 递归
Understanding
首先,导入库 stdbool stdio stdllib time
接着程序构建了 person 结构体,内置了一个大小为 2 的 parent 指针,大小为 2 的 allels 字符串
初始化一些常量,generation,indent length。
函数声明person *create_famliy(int generations);以及打印家庭,释放内存,随机血型等函数功能
然后进入 main 函数,main
函数不接受命令行输入参数,由 srand(time(0))开始,利用当前时间生成随机种子;
调用 create_family 函数并赋值给 person 类型的指针 p
createfamliy 函数为 person 型指针赋值,
print_family(p,0);接受两个参数,用于输出家庭血型
最后释放内存 free_family(p);
来看声明函数的细节person *create_family(int generations)
首先,为 new person 分配内存
接判断:还有下一代,则继续创建 new person
然后为其创建父指针,然后为其分配血型
任何非 generation > 1 的情况,即第 0 代,设置父指针为 NULL 并随机设置血型
出判断,返回创建的 new person;return NULL;
void free_family(person *p)
三项代办:handle base case ;free parents recursively; free child; 其实是我没看懂要干嘛
void print_family(person *p,int generation)
本部分代码已给出,同样有 handle base case
即首先进入判断 若 p == NULL 则返回
出判断,进入打印空字符的循环,用于输出格式化
再进判断,用于输出 person,当 generation == 0 输出子代血型信息
其他判断条件同理
最后调任两次自身以输出亲代信息(大概
char random_allele()
用于随机选择血型,基于随机数 mol 3 的余数进行赋型。
Walkthrough
开始着手后发现还是回去练练 malloc 再说吧搞定,写完再回头看真的挺简单的。
对于地址型的函数,若 malloc 失败应返回 NULL
关于字符串,其实就是 array
递归地使用函数
SourceCode
1 | |
Speller
Before coding
目标:最快的拼写检查器!
Background
由于内容的复杂性,程序被拆分为多个子程序,详情见 understanding。
Vocabulary
theoretical 理论上
asymptotically equivalent
implement
prototype
benchmark
Understanding
dictionary.h
内涵一些新语法,但是不必太过关心
注意下#include <stdbool.h> 因为我们现在不再使用 cs50 库了
另一个点,#define 是 预处理器指令,定义了 length 的值为 45,写于文件开头,便于查找更改
接着声明函数。
dictionary.c
导入刚才的函数声明头文件
定义了一个哈希表的节点变量类型,内涵一个字符类,next 指针.使用 unsigned int 定义
“unsigned int” 是 C 语言中的一种数据类型,它表示一个无符号整数。这意味着它只能存储正数或零,不能存储负数。这与 “int” 类型不同,后者可以存储正数、负数和零。”unsigned int” 的范围通常是从 0 到大约 4,000,000,000
然后留了一个 TODO,让我们来选出哈希表里的 buckets,此外还实现了最基础的 load,check,size,unload 功能
speller.c
此文件无需修改
注意,我们使用了getrusage预处理器指令,前文#undef 即 undefine 取消定义之前定义过的宏,后续代码就可以使用 getrusage 而不会被预处理器替换掉。
定义了 speller 的用法为 speller [dictionary] text其中 dictionary 是一个存储字母的列表文件,如果没有指定字典种类,则默认使用 dictionary/large;后面的 text 为待检测文本,需要待 load 函数成功读取 text 才可以正常运行,否则会提示 could not load
此处仅介绍 speller 的用法。
text/
存储了一堆文本的文件夹。
Specification
请按照 load,hash,size,check,unload 的顺序设计程序
尽可能使 time 更小
不要修改 speller 和 Makefile
不要修改 dictionary.c/h 中已经给出的函数声明
可以修改 N 的值
拼写检查无需关心大小写
记得用 valgrind 检测内存泄漏
Walkthrough
根据提示,优先处理 load 函数,含有一个字符串 dictionary 指针参数。
读取 dictionary 中的内容并写入哈希表,最后关闭字典。使用哈希表在哪里?……好喜欢这种刚拿到题目手足无措的感觉。没什么思路,重新看看 spell.c 的运行逻辑…
看完了,准备开工。
bool load(const char *dictionary)
加载字典,成功返回 ture,失败返回 false。
如何将文件读入内存?定义一个文件类型的指针 FILE *source
欢迎来自 stdio 库的文件读写相关函数 fopen,fread,fclose!
fopenfopen(“filename”,”mode”)
模式:r - read; w - write; a - append
返回值:打开的文件指针,失败返回 NULL
注意:随手跟 fclose 函数关闭文件;使用双引号。
freadfread(指向读入数据的第一位地址指针,每组读取内容的大小,每次读取几组,指向源文件 ie.使用 fopen 的文件指针)
fcloseif (filepoint != NULL) fclose(filepiont);
好,将字典文件读入内存吧,当文件成功打开时,需要创建一个缓冲区将字典全部存储进内存:char buffer[size?]size 应为字典的大小,如何得知?
在 C 语言中,你可以使用 fseek 和 ftell 函数来确定文件的大小。首先,你可以使用 fseek 函数将文件指针移动到文件的末尾,然后使用 ftell 函数来获取当前的文件位置,这就是文件的大小。这是一个基本的示例:
1 | |
在这个例子中,size 变量就是文件的大小,单位是字节。注意,你需要在使用 ftell 函数之后使用 fseek 函数将文件指针重新定位到文件的开始,否则后续的读取操作可能会失败。
完成读取后关闭文件并返回 true。你先别急
将读取的内容存入哈希表待查,哈希函数生成唯一值,直接读取数列中用同一函数生成并存储的对应值
you
哈希表和字典树有什么区别
ddb
哈希表和字典树(Trie)都是用于存储和查找数据的数据结构,但它们的工作方式和效率有所不同。
哈希表通过使用哈希函数将键(通常是字符串)转换为数组的索引。这使得查找、插入和删除操作的时间复杂度可以达到 O(1)。然而,哈希表的一个主要问题是碰撞,即当两个键的哈希值相同时,需要一种方法来处理这种情况。
字典树,又称前缀树,是一种特殊的树形数据结构,用于存储一种特殊类型的信息,通常是字符串。每个节点表示一个字符串(或者字符串的一部分),从根节点到任何节点的路径都可以表示一个字符串。字典树的主要优点是查找效率高,特别是对于查找前缀或者进行自动补全等操作。但是,它可能需要更多的空间来存储数据。
在 CS50 的 Speller 问题集中,我们推荐使用哈希表,因为它在处理大量数据时通常更加高效。
哈希表如何运行?我去写一个先,见 Note 哈希表
偷偷看了 walkthrough,给出了比 fseek 更好的方案:
将字典内的值赋给哈希表,可以使用 string 库的 strcpy 函数strcpy(n->word,"hello");
使用 hash 函数获得每个字符串的哈希值fscanf(file, "%s",word); //return EOF if reaches file's end
设置一个循环:当返回值不为 EOF 时,新建节点,计算哈希值,设置哈希表;读至文件最后一行返回 true
设置哈希表有两种方法,头插法和尾插法
尾插毕竟简单,table[index]->next = n; 这句的作用是将新节点添加到链表的尾部。它首先找到当前链表的最后一个节点(table[index]),然后将这个节点的 next 指针指向新节点。这就完成了在链表尾部添加新节点的操作。
头插法稍微有点复杂,将表头赋给 new_node->next,相当于把前一个节点的指针塞到新节点的 next 里,再把新节点赋值给头指针。
这两种方法的主要区别在于新节点添加的位置不同,一个是添加到链表头部,一个是添加到链表尾部。在哈希表中,通常使用头插法,即将新节点添加到链表头部,因为这种方法的操作更简单,时间复杂度为 O(1)。而尾插法需要遍历整个链表,时间复杂度为 O(n),在链表较长时效率较低。
hash()
CS50 给了一个哈希函数:以首字母的值设置索引;计算每个 word 的 ASCII 值之和;根据单词长度设置索引
总之,尽量避免冲突!并且让哈希值在 buckets 里均匀分布
1 | |
注意修改哈希函数会导致所需 buckets 变化,需同步修改:
1 | |
也可以直接这样:return strlen(word);
size()
计算有多少个词,完全不知道怎么写。。。看看 walkthrough,才 26 秒!?
load 时记数啊
问问鸭子…哦,原来可以在几个函数体外增加全局变量,那就简单了,定义一个 count = 0,在 load 循环里加一句 count++,在 size 里如果 load 为真直接返回 count。
check()
检验词汇是否存在于字典中
首先调用哈希函数查找该词,然后直接用 strcasecmp 函数检验(忽略大小写, 另:该函数位于<string**s**.h>中, 而非<string.h>)
实操:获取哈希值 length,ptr 指针直接进入第 length 个桶遍历哈希表,循环条件:该链非空; 判断:词相同,返回真,不同,将 cursor 下一个指针(next)赋值给 cursor;cursor 为空时退出循环,返回 false,表示无该词。
unload()
释放所有内存。
不能直接 free(table)会造成表头下的链全部泄漏
再用一个 cursor 遍历,temp 循环释放内存
注意返回 true 的时机,须所有内存均释放
1 | |
或者递归
使用 valgrind 检测内存泄漏
SourceCode
【已编辑】
保留了一部分比较关键的实现。
1 | |